1. What is feature scaling? Feature scaling is a method used to normalize all independent values of our data. We also call it as data normalization and is generally performed before running machine learning algorithms. 2. Why do we need to use feature scaling? In practice the range of raw data is very wide and hence the object functions will not work properly (means that it will stuck at local optimum), or they are time-consuming without normalization. For example: K-Means, might give you totally different solutions depending on the preprocessing methods that you used. This is because an affine transformation implies a change in the metric space: the Euclidean distance between two samples will be different after that transformation. When we apply gradient descent, feature scaling also helps it to converge much faster that without normalized data. With and without feature scaling in gradient descent 3. Methods in feature scaling? Rescaling The simp...
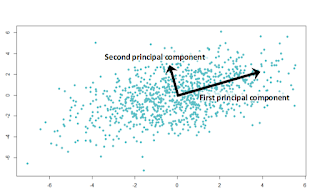
I. What is manifold learning Dimensionality Reduction The accuracy of the training algorithms is directly proportional to the amount of data we have. However, managing a large number of features is usually a burden to our algorithm. Some of these features may be irrelevant, so it's important to make sure that the final model doesn't get affected by this. What is Dimensionality? Dimensionality refers to the minimum number of coordinates needed to specify any point within a space or an object. Why do we need Dimensionality Reduction? If you keep the dimensionality high, it will be nice and unique but it may not be easy to analyse because of complexity involved. Apart from simplifying data, visualization is also an interesting and challenging application. Linear Dimensionality Reduction Fig 1 : PCA illustration (source: http://evelinag.com/blog ) Principle Component Analysis Given a data set, PCA finds the directions along which the d...
(Maximum Inner Product Search) Given a set of points $S \in R^D$ of size N , and a query point $q$ . Determine : $x^{*} = \mathrm{arg} \max_{x \in S}q^Tx$ In this presentation, I will introduce the problem of Maximum Inner Product Search (MIPS) and a series of Locality Sensitive Hashing (LSH) methods to solve MIPS in sub-linear time. Reference papers are included in the below slides. Presentation slides: Locality Sensitive Hashing for Maximum Inner Product Search . Presenter: Dung Le.

Comments
Post a Comment