Feature scaling

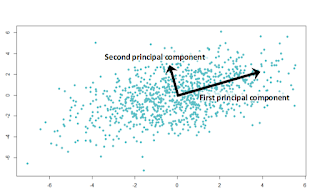
1. What is feature scaling? Feature scaling is a method used to normalize all independent values of our data. We also call it as data normalization and is generally performed before running machine learning algorithms. 2. Why do we need to use feature scaling? In practice the range of raw data is very wide and hence the object functions will not work properly (means that it will stuck at local optimum), or they are time-consuming without normalization. For example: K-Means, might give you totally different solutions depending on the preprocessing methods that you used. This is because an affine transformation implies a change in the metric space: the Euclidean distance between two samples will be different after that transformation. When we apply gradient descent, feature scaling also helps it to converge much faster that without normalized data. With and without feature scaling in gradient descent 3. Methods in feature scaling? Rescaling The simp...